Containers at Scale
A Containers Journey
The article is oriented to an organisation’s systems, be in public or internal, and not to product shipping businesses. Using Kubernetes as the example runtime platform is for demonstration purposes only, and this journey is not specific to any given runtime platform. From software development, testing and runtime environments, there are different points of focus and scale.
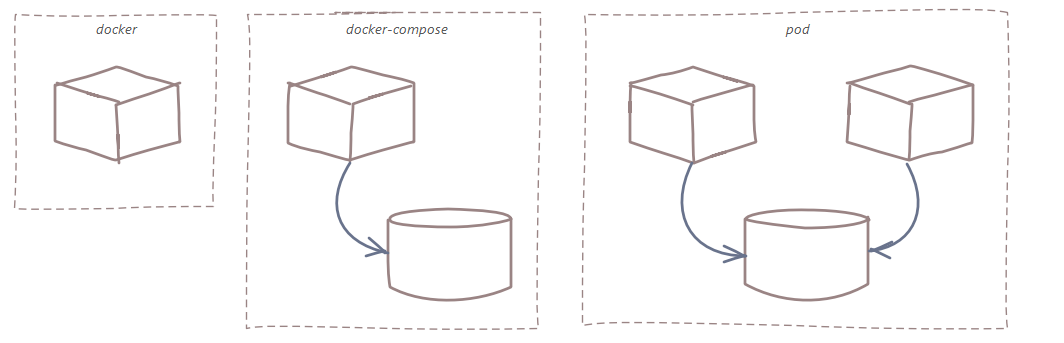
Commonly, the development viewpoint may not extend beyond docker (or even local), however when function testing the software, a production like environment is necessary, which is when docker-compose provides a declarative mechanism for creating a testable environment, with code that can be reused in the delivery pipeline and shared among team members. Once the container is verified production ready, it can be scaled and made highly available by the runtime platform, i.e. Kubernetes.
A consistent approach to build and run is applied, where the build image fulfills dependencies and, where applicable, compiles the application. The resulting software package is retained as an artifact. In the docker-compose environment, the software package is built into the runtime image, which is then tested. The runtime image will not support debug and will have any dependency resolution tools or compilers. Once the image has been tested, it is then pushed to the image registry.
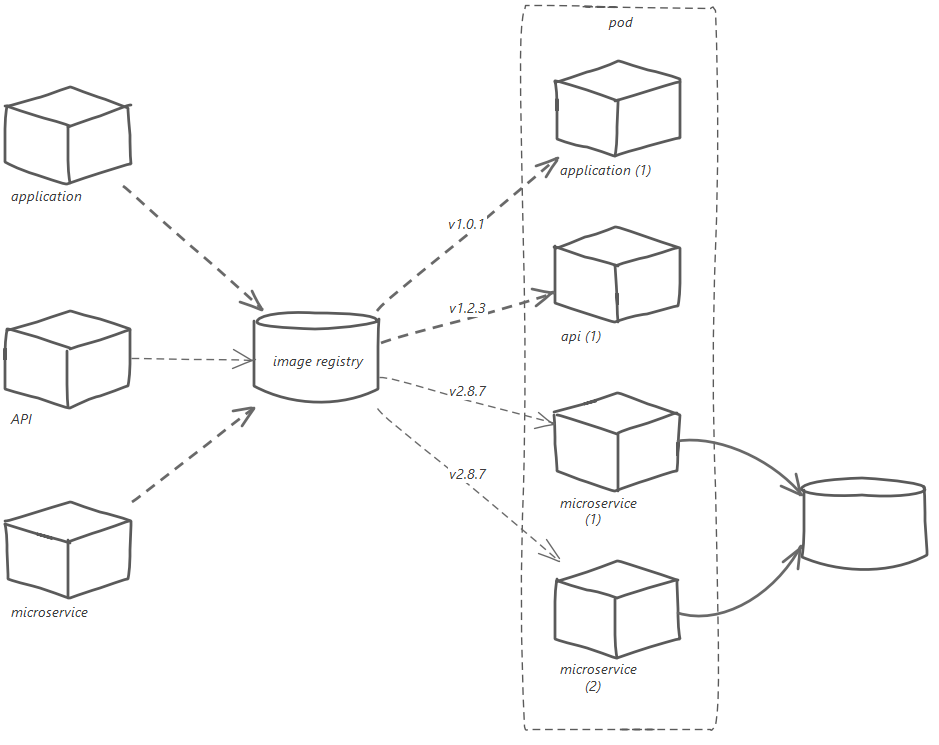
An application does not live in isolation however. Value streams combine microservices, API’s and applications to provide a solution. This solution must be repeatable and promotable across production and non-production environments. Following is an example journey is served by a number of capabilities, and the value stream realisation is only achieved when all of the capabilities are working in harmony. To fulfil a capability, many components maybe involved.
All the components are defined within the solution. The complete solution is definition is static at a point in time, i.e. the release, which has a unique identification. The release is promoted through each environment as a manifest of the versioned components, and merged with configuration information at deployment time. Environment configuration will include secrets, end-points and scale, e.g. in production, there are two instances of the microservice.
Why?
This appears to add an overhead to simply getting the developer to deploy to our user environments? This imperative approach is the dominant model for in-house, bespoke development, so why would we differ?
Focus
We want our developers to focus on building great code! Developers creativity should be concentrated on great features and functions, not pushing code to environments with long conference calls to orchestrate each of the teams.
Empowerment
With the development team being independent to the deployment process, business users, i.e. test managers, product owners or stream leads can be empowered to gate releases into their environment whenever they want without engaging a large number of people to perform a complex set of steps.
Predictability
Environment owners need to be confident that the solution they have been delivered contains all the components at the agreed version levels.
Scalability
If another environment is required, it can be created and deployed to from a single pipeline, instead of having each team extend their pipelines for the new environment.
Drift
If an environment has been compromised and hot-fixed out of band, executing the release will remediate this drift and return it to a known state.
Disaster Recovery
Should an environment be lost, it can be redeployed from a specific release to reinstate it.
So what does it look like? See following article, Autonomous Development, Authoritative Release.